Solución de problema de rendimiento de vSphere con QoS de ONTAP
En las infraestructuras IT basadas en virtualización, los servidores virtuales comparten los recursos físicos de los servidores físicos (CPU, RAM, red y disco). Con el uso de cabinas de almacenamiento externas por parte de estos hipervisores, también los recursos de almacenamiento externo con compartidos, como las tarjetas o HBAs, los switches y los volúmenes o LUNs. En el caso de que uno de los servidores virtuales incremente el consumo de uno de los recursos físicos, el resto de servidores virtuales que comparten el recurso físico pueden ver afectado su rendimiento tras una congestión del recurso y manifestándose a través del incremento de la latencia.
Una arquitectura muy extendida es la compuesta por virtualización de VMware con vSphere y almacenamiento de NetApp con ONTAP a través de NFS. En esta solución los discos virtuales vdisk de los servidores virtuales son ficheros dentro del volumen de ONTAP.
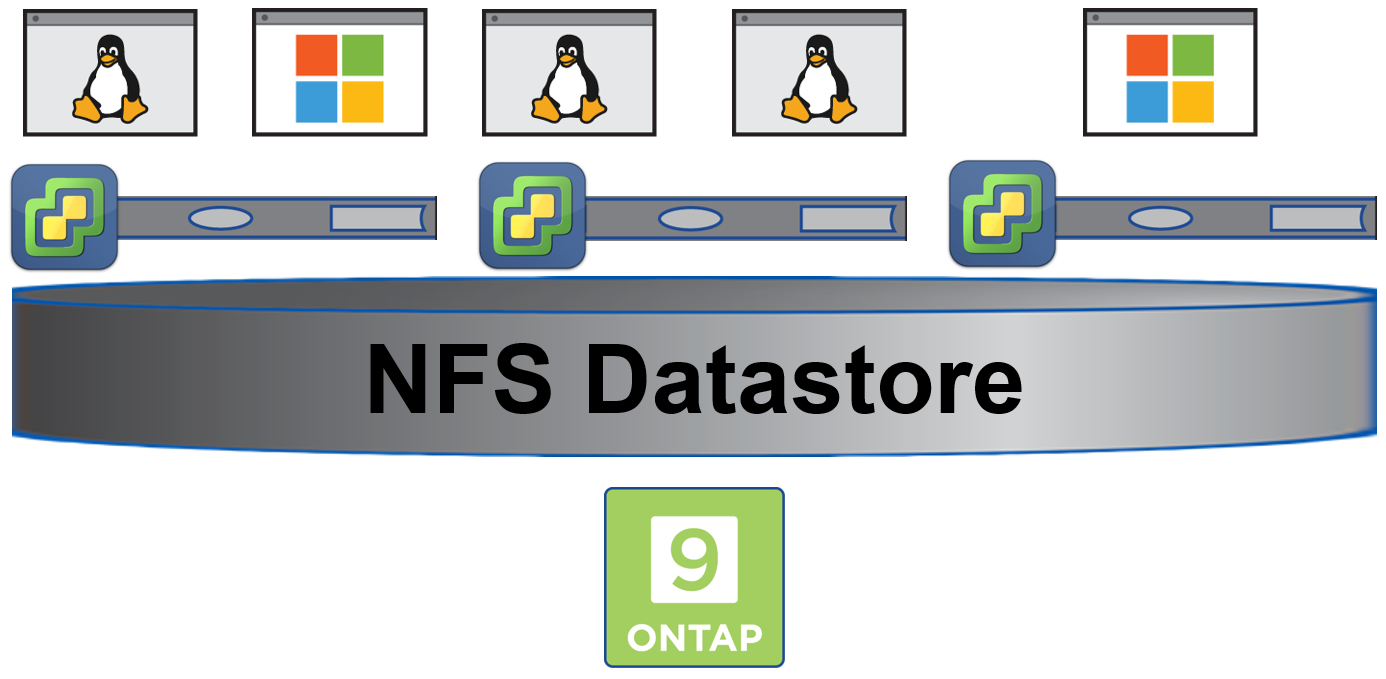
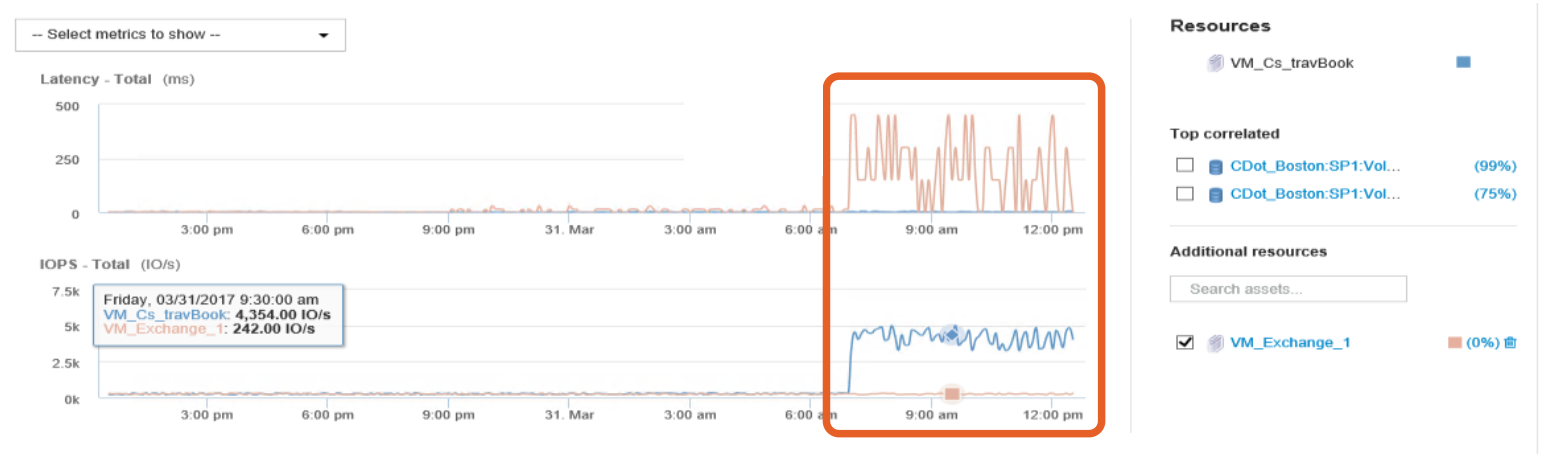
El escenario donde un servidor virtual consume muchos recursos de almacenamiento IOPS y produce problemas de rendimiento al resto de servidores que comparten almacenamiento puede no ser a veces fácil de detectar. El software de NetApp OnCommand Insight es la herramienta perfecta para, entre otras cosas, este tipo de situaciones. A continuación se observa un ejemplo donde se correlaciona el incremento de latencia en un servidor virtual con el incremento de IOPS de otro servidor virtual.
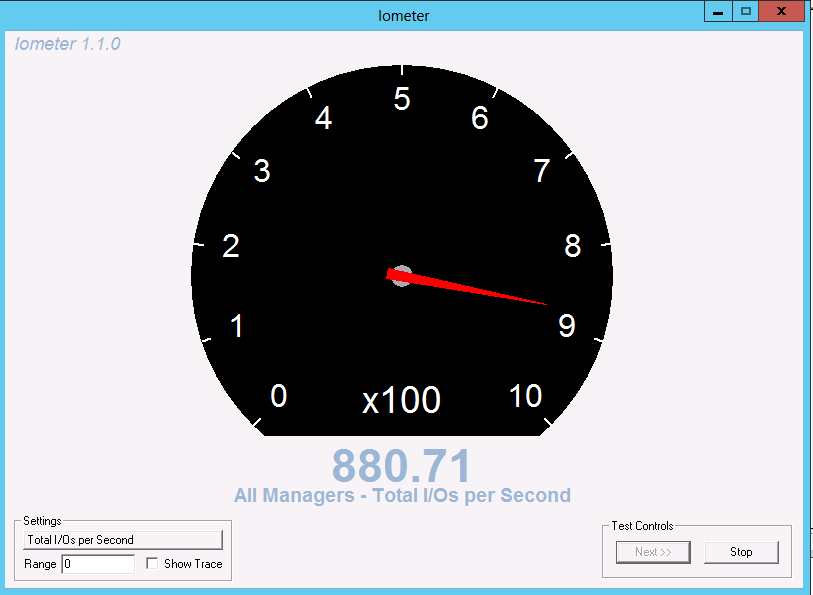
Sin este software, y habiendo localizado previamente el volumen que está recibiendo la ingesta de operaciones, por ejemplo con el software OnCommand Performance Manager, se puede hacer con algo de mayor esfuerzo de forma manual. A continuación se muestra los posibles pasos a seguir para la detección y solución. Para ello se ha ejecutado el software IOmeter en un servidor SQL generando carga sobre un disco vdisk que reside en un volumen NFS de una cabina ONTAP.
Detección
Con el comando qos statistics se observa un resumen del rendimiento del sistema. Este es un ejemplo por lo que no hay ninguna carga mas significativa.
cluster1::> qos statistics performance show -refresh-display true
Policy Group IOPS Throughput Latency Is Adaptive?
-------------------- -------- --------------- ---------- ------------
-total- 964 29.76MB/s 496.00us -
User-Best-Effort 952 29.76MB/s 503.00us false
_System-Work 7 2.71KB/s 0ms false
_System-Best-Effort 5 0KB/s 0ms false
Conociendo el volumen NFS, con el comando statistics top file se observan los ficheros con más carga del nodo que posee ese volumen.
cluster1::> statistics top file show -node cluster1-01
cluster1 : 4/11/2018 07:23:41
*Estimated
Total
IOPS Node Vserver Volume File
---------- ----------- ------- ------ ----------------------------------------------------------------------
875 cluster1-01 svm1 nfs1 /Svr2012-SQL1/Svr2012-SQL1-flat.vmdk
73 cluster1-01 svm1 nfs1 /Svr2016/Svr2016-flat.vmdk
45 cluster1-01 svm1 nfs1 /Svr2012-1/Svr2012-1-flat.vmdk
11 cluster1-01 svm1 nfs1 /CentOS-1/CentOS-1-flat.vmdk
Viendo la salida del comando anterior, se observa que hay un vdisk que está teniendo mucha mas carga que el resto, 875 IOPS. Se crea una nueva política de QoS para poder obtener mas métricas, con un máximo de 20000 IOPS, muchísimo mas que la carga actual.
cluster1::> qos policy-group create -policy-group svm1-sql -vserver svm1 -max-throughput 20000
cluster1::> qos policy-group show
Name Vserver Class Wklds Throughput
---------------- ----------- ------------ ----- ------------
svm1-sql svm1 user-defined 0 0-20000IOPS
Se aplica la política creada al fichero vdisk.
cluster1::> volume file modify -vserver svm1 -volume nfs1 -file "/Svr2012-SQL1/Svr2012-SQL1-flat.vmdk" -qos-policy-group svm1-sql
Con el mismo comando qos statistics se observa ahora el detalle de la carga del QoS configurado.
cluster1::> qos statistics performance show -refresh-display true
Policy Group IOPS Throughput Latency Is Adaptive?
-------------------- -------- --------------- ---------- ------------
-total- 1000 30.82MB/s 507.00us -
svm1-sql 986 30.82MB/s 512.00us false
_System-Work 5 0KB/s 0ms false
_System-Best-Effort 5 0KB/s 0ms false
User-Best-Effort 4 0.22KB/s 436.00us false
También se puede observar la latencia que se tiene de cada carga y de qué capa se tiene esa latencia. Se observa como la latencia de la política svm1-sql viene dada por las columnas Network, Data y Disk.
cluster1::> qos statistics latency show -refresh-display true
Policy Group Latency Network Cluster Data Disk QoS NVRAM Cloud
-------------------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
-total- 475.00us 108.00us 0ms 147.00us 220.00us 0ms 0ms 0ms
User-Best-Effort 787.00us 598.00us 0ms 176.00us 0ms 0ms 13.00us 0ms
svm1-sql 473.00us 105.00us 0ms 147.00us 221.00us 0ms 0ms 0ms
Solución
Una vez identificado el problema, y para evitar que la carga de ese servidor virtual afecte al resto, se puede por ejemplo limitar el uso de IOPS de ese vdisk de tal forma que no congestione el sistema y, por tanto, mejore el rendimiento del resto de servidores.
Para ello simplemente se modifica la política de QoS creada bajandola a un máximo de 200 IOPS.
cluster1::> qos policy-group modify -policy-group svm1-sql -max-throughput 200
En ese momento se observa que el software IOmeter reduce la carga sobre el disco.
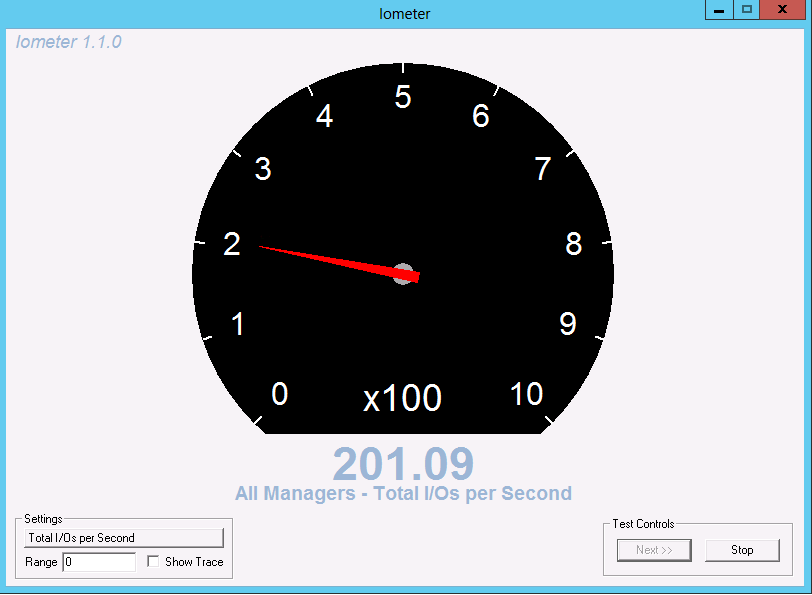
Con el mismo comando qos statistics se puede ver como ha bajado los IOPS a esa carga, frenando el acceso y, por tanto, aumentando la latencia.
cluster1::> qos statistics performance show -refresh-display true
Policy Group IOPS Throughput Latency Is Adaptive?
-------------------- -------- --------------- ---------- ------------
-total- 312 6.73MB/s 3.01ms -
svm1-sql 215 6.73MB/s 4.32ms false
_System-Work 95 3.92KB/s 105.00us false
User-Best-Effort 2 0.14KB/s 173.00us false
Con el comando ya visto anteriormente se observa como la latencia de la política svm1-sql viene dada principalmente por la columna QoS.
cluster1::> qos statistics latency show -refresh-display true
Policy Group Latency Network Cluster Data Disk QoS NVRAM Cloud
-------------------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
-total- 4.27ms 113.00us 0ms 172.00us 342.00us 3.64ms 0ms 0ms
svm1-sql 4.28ms 113.00us 0ms 172.00us 342.00us 3.65ms 0ms 0ms
User-Best-Effort 115.00us 70.00us 0ms 45.00us 0ms 0ms 0ms 0ms